
The Observation
There's a pattern I keep seeing in teams adopting AI-first development. They write elaborate rules files. They craft meticulous skill documents. They spend hours on system prompts that say things like "always add translations for all supported languages" or "never put inline comments in production code." And that's smart. Those rules give the AI agent the best possible shot at getting it right on the first try.
But then the agent forgets. Or interprets the rule differently. Or follows it nine times out of ten but misses the tenth, and that's the one that ships.
The rules aren't the problem. They're necessary. The problem is that most teams stop there. They treat rules as the quality strategy instead of one layer of it. We're asking probabilistic tools to behave deterministically, and then acting surprised when the output is, well, probabilistic.
There's a complementary pattern that makes the whole thing work. One that's been staring us in the face for decades. (If you've read Shifting Gears, you'll recognise the "encode every repeated mistake" principle, this is where that idea really comes alive.)
The Shift: Instructions Plus Guardrails
The insight is almost embarrassingly simple: don't just tell the AI what to do. Also make it impossible to do the wrong thing.
Think about it from the agent's perspective. When you give it a rule, you're asking a language model to hold one more thing in its context window, alongside your codebase, your instructions, your conversation history, and whatever else it's juggling. That rule gives it the best chance of getting it right. But sometimes it forgets. Sometimes it doesn't. You can't control that.
But when you also give it a test that fails, you're giving it something it understands perfectly: a red signal. A concrete error message. A thing that needs to be fixed before the job is done. The rule points it in the right direction. The test catches it if it drifts. One is probabilistic. The other is deterministic. Together, they're incredibly powerful.
A rule is a hope. A failing test is a fact. You want both.
What This Looks Like in Practice
I lead engineering at AutoUncle. Over the past months, as we've gone deeper into AI-first development, I've deployed more automated validators than in the previous five years combined. Not because I suddenly care more about code quality. Because the cost of building these validators has dropped to nearly zero, and the value they provide has skyrocketed.
The principle applies regardless of your stack. Every language ecosystem has these tools. What matters isn't which linter you use, it's that you use one, configured to enforceyour conventions, and that it runs automatically.
Here are the categories of checks that matter most:
A custom test that scans every translation key across all locale files. It checks that every key exists in every language, that the structure is consistent, and that no keys are orphaned. When the AI agent adds a new feature and forgets to add the Danish translation, the test fails. The agent sees the failure, understands it immediately, and fixes it. No rule needed. You can build this in any framework that uses locale files, Rails i18n, next-intl, Flutter ARB files, whatever you're working with.
Standard linting tools configured to enforce your specific conventions. Not just "valid CSS", your CSS. Your naming patterns. Your file structure. ESLint for JavaScript and TypeScript. Stylelint for CSS. Pylint or Ruff for Python. RuboCop for Ruby. Clippy for Rust. The AI doesn't need to know the convention. It just needs to see the lint error and fix it.
Beyond the defaults, most linting tools let you write project-specific rules. One checks that certain types of comments never appear in production code. Another enforces naming conventions for service objects or React components. These aren't in a rules file, they're in the CI pipeline, and they're non-negotiable. ESLint custom rules, RuboCop custom cops, Pylint plugins, custom Roslyn analyzers for C#, every ecosystem has a way to do this.
Automated security scanners that catch vulnerabilities before they ship. Brakeman for Ruby, Bandit for Python, npm audit or Snyk for JavaScript, Trivy for containers. FOSS compliance checkers that flag problematic licenses. These used to feel like "nice to have." Now that AI agents can introduce dependencies you've never heard of, they're essential.
Every one of these tools existed before AI. Linters aren't new. What's new is the economics. Building a custom validator used to be an investment, you'd weigh whether the time spent was worth the time saved. Now? You can ask the AI agent itself to build the validator in minutes. The cost has collapsed. The value has exploded.
A Real Example: The CoDriver Pipeline
Let me get concrete. I recently did an overhaul on one of our internal projects, CoDriver, a Ruby on Rails application, and deployed every static and dynamic analysis tool I could justify. Not as a theoretical exercise. Because I was building features with AI agents daily, and I needed the safety net to be airtight.
Here's what the CI pipeline looks like now. Every single one of these checks runs automatically on every push:
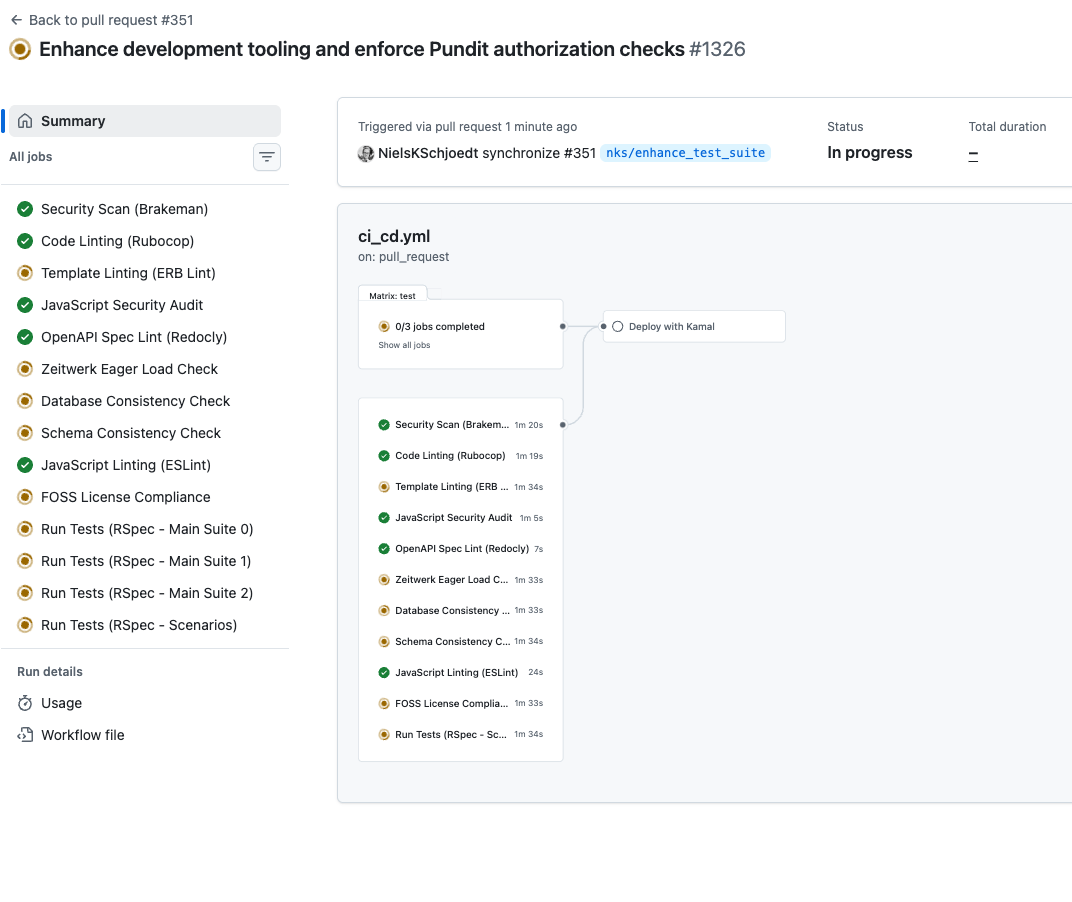
That's Brakeman for security scanning. RuboCop with plugins for Rails-specific linting, Pundit authorization checks, and database anti-pattern detection. ERB linting and style checks for templates. JavaScript security audits. OpenAPI spec validation to make sure our APIs follow the spec. Zeitwerk eager loading checks to catch class and inheritance issues. A database consistency checker that flags missing indexes and best-practice violations. Schema consistency checks to ensure the schema dump is always in sync with migration files. JavaScript linting. FOSS compliance checking. And on top of all that, the full spec suite, 4,500 tests that cover close to 100% of the codebase, which means even the dynamic analysis tools catch things like N+1 queries that static analysis can't.
You can tell an LLM to be mindful about N+1 queries. But if you deploy a tool that flags it when it actually happens at runtime, you're better off. That saves your ass in production. Every time.
But here's the part that really matters: these checks don't just run in CI.I've wired them into the local development workflow through slash commands and skills in Cursor. A single command spins up sub-agents that run all of these checks in parallel, locally, in about one to two minutes. The developer, or the AI agent, gets the feedback immediately, not twenty minutes later when CI fails and your context has moved on.
That's the difference between retrospective quality enforcement and proactive quality enforcement. If the agent discovers failures while it's still working on the task, it can fix them on the spot. If it discovers them after CI runs, you've already switched contexts, and the fix becomes a chore instead of a natural part of the flow.
The Feedback Loop That Changes Everything
Here's where it gets powerful. When an AI agent runs against your codebase and a linter catches something, something magical happens: the agent gets immediate, specific, actionable feedback.
Not a vague rule it might forget. Not a skill document it might misinterpret. A concrete error message with a file path, a line number, and a clear expectation. The agent reads the failure, understands what went wrong, and fixes it. Usually on the first try.
This is the pattern: let the agent work freely, then let your automated guardrails catch what it misses. You're not micromanaging the AI. You're building a system where mistakes surface automatically and get corrected as part of the normal flow.
It's the same principle as test-driven development, but applied to the AI collaboration itself. The tests don't just validate the output. They're part of the communication channel between you and the agent.
Rules Still Matter, Enforcement Makes Them Stick
I want to be very clear about this: rules, skills, and well-crafted prompts are not optional. They are the foundation. A good rules file tells the agent how to approach problems, what architecture to follow, what style to aim for. Skills give it the playbooks for specific tasks. Without these, the agent is guessing. With them, it gets things right most of the time.
But "most of the time" isn't good enough for production. Rules are aspirational. They describe what should happen. Enforcement guarantees it does. These aren't competing strategies, they're complementary layers that reinforce each other.
Think of it like building codes versus building inspections. The code tells you what the building should look like. The inspection catches it if it doesn't. You need both. Remove the code and inspectors don't know what to check. Remove the inspections and buildings fall down. The magic is in the combination.
The sweet spot is layered: rules set the intent. Linters and validators enforce it. The AI agent operates between these layers, guided by the rules, corrected by the checks. The rules give it the best chance of nailing it on the first attempt. The enforcement catches it when it doesn't. Together, you can run at full speed with confidence.
The Meta-Pattern: Continuous Learning
There's a second observation that builds on the first, and it's even more powerful.
Every time you build a feature with an AI agent, you learn things. You discover edge cases. You spot patterns the agent handles poorly. You make decisions about naming, structure, or behaviour that become project conventions.
Most of the time, these learnings evaporate. They exist in your head, or buried in a conversation transcript, or in a PR comment nobody will read again.
The fix is a meta-procedure, a habit, really, that captures these learnings and turns them into permanent infrastructure.
Every feature you build should leave behind a stronger safety net for the next one.
Here's what the pattern looks like in practice: every time you start a new task, you maintain a simple markdown file alongside it. Call it learnings.md, or decisions.md, or whatever fits your style. As you build, you note down anything that qualifies as a best practice, a global decision, or a "we should always do it this way."
Then, at the end of the task, before you move on, you consolidate those notes. Some become updates to your rules file. Some become new linter configurations. Some become entirely new custom validators. The key is that nothing stays informal. Everything either becomes a rule (aspirational) or a check (deterministic).
1. Build, Work on the feature with your AI agent, as normal.
2. Capture, Note learnings, decisions, and patterns in a side file as they emerge.
3. Consolidate, At the end of the task, turn notes into permanent rules, linter configs, or custom tests.
4. Compound, The next task starts with a stronger set of guardrails than the last.
This is a compounding quality flywheel. Every feature you ship makes the next feature safer, faster, and more consistent. Your rules get sharper. Your validators get more specific. Your CI pipeline catches more. And the AI agent, because it operates within this tightening system of checks, produces higher-quality output with each cycle.
Why Now? The Economics Changed.
None of this is conceptually new. Linters existed before AI. Custom test suites existed before AI. The idea of learning from your work and improving your processes has been around since the Toyota Production System.
What changed is the economics.
Building a custom linter rule used to take hours. You'd weigh the investment: is it worth spending half a day to catch a problem that happens once a month? Usually the answer was no. So you'd write a wiki page instead, or add a comment to the PR template, and hope people read it.
Now? You tell your AI agent: "Write me a custom linter rule that ensures all service classes follow the naming convention and include a standard entry point." Or: "Create an ESLint plugin that flags React components missing display names." Or: "Add a Pylint checker for our internal API call pattern." Five minutes later, you have it. Running in CI. Forever. This is what I mean when I write about the cost of software hitting zero, and it applies to the tools that keep your software honest just as much as to the software itself.
The same goes for test suites. Want a test that checks every translation file has the same key structure? That used to be an afternoon project. Now it's a conversation. Want a linter that ensures no template has inline styles? A few minutes. Want a schema drift detector that catches when your migrations and your ORM models are out of sync? Ask the agent. It'll build it before your coffee gets cold.
This is why I'm deploying more validators now than ever before. Not because I trust AI less. Because building the guardrails has become nearly free, and the determinism they provide has become invaluable.
We're in a transition phase. AI is extraordinary, but it's not perfect 100% of the time. It gets things right 90, 95, maybe 98 percent of the time with good rules and skills. That last few percent is where things ship broken. And the cost of closing that gap? A few extra CI minutes. That's it. A handful of CPU cycles on every push in exchange for the confidence to merge and deploy without a human standing guard at every gate. That's not a cost. That's one of the cheapest investments in quality you'll ever make.
The Hierarchy of AI Quality Assurance
If I were to rank the layers of quality assurance in an AI-first workflow, it would look like this, from weakest to strongest:
The first level is where most teams are today. They've adopted AI tools, but quality enforcement is still mostly vibes-based. "It usually gets it right." "We'll catch it in review." "The prompt says to do it this way."
The second level is better, structured rules files, skills documentation, project conventions written down. This is where a lot of the AI tooling conversation lives right now, and it's a meaningful step. It gets you to 90%+ quality. But it's still probabilistic.
The third level is where most teams stop too early. Almost every project has somelinting and maybe a basic test suite. But in the AI era, you can take this to a completely different level. Custom linter rules that enforce your specific architectural patterns. Security scanners that catch vulnerabilities the agent introduced. Schema validators, translation integrity checks, performance anti-pattern detectors, all built in minutes by the AI agent itself. The cost of building these has collapsed. Most teams could deploy ten times more automated checks than they have today, and the only cost is a few extra minutes of CI time. The return is deterministic quality at a velocity that would have been reckless without the safety net.
Start Here
If this resonates, here's where to begin. You don't need to overhaul your entire pipeline. Pick the one thing your AI agent gets wrong most often. The one convention it keeps forgetting. The one standard that keeps slipping through.
Now build a check for it. A linter rule. A test. A validator. Something that runs in CI and fails loudly when the standard is violated.
Then do it again next week. And the week after.
Within a month, you'll have a system that catches the things your rules couldn't enforce. You'll spend less time reviewing AI output and more time building. And every feature you ship will leave behind a stronger foundation for the next one.
That's the real workflow: build, learn, enforce, compound.
Don't just tell it. Enforce it.
For the broader principles behind working with AI agents, including skills, context management, and planning, see the AI Cookbook. For the emotional and cultural side of letting go of old engineering practices, there's It Wasn't Wrong. The 79 Questions covers everything from code quality concerns to how AI handles nondeterminism. And if you want to see how these enforcement principles extend to production, monitoring, observability, and giving AI access to your entire ops stack, read Still True.